精读vuejs设计与实现
diff算法(diff:差速器)
虚拟dom其实就是一个JavaScript对象,是真实dom的一个副本,因为直接对真实dom操作的消耗很高。diff算法(属于渲染器,就是将虚拟dom转换成真实dom)便是用于对比新旧虚拟dom的,并找出其中的差异,并尽可能优秀的改变差异。
虚拟DOM缺点:虚拟DOM无法预知,那么每次都需要重新生成一个DOM树并进行遍历比较。尽管有时候可能并未改变。
vue中的优化:
- 静态提升。对于很多静态节点,并不需要改变。因为没有响应式数据的话以后也很难改变。这一类节点需要提升。在以后渲染的时候都可以使用这一部分相同的节点(VNode)。
- 修补标记。对于绑定了响应式数据的节点,是有可能会改变的。所以对于这一类节点可以添加一个标记,并将其移入到对应的父节点的
dynamicChildren(动态子节点)数组中(带有该属性的父节点称作块:Block)。
那么以后遍历的时候便直接去dynamicChildren中对比修改即可。
diff算法的作用:主要是用来计算两组子节点的差异,并试图最大程度上复用DOM元素。
简单的diff算法
比较:先找到两组新旧子节点中最短的节点数组,并遍历它,同时给调用patch函数(更改节点的内容,或者对不同type的节点进行更新卸载)进行补丁。最后再比较到底是新数组长还是旧数组。若是旧数组,说明有dom需要被卸载;反之则是需要被挂载。key的作用:比较中说,需要遍历短的数组,但可能出现移动位置、删除(添加)某个不确定位置的节点,key的作用就是找到可以进行复用的节点。key值相当于身份证,在每一次遍历的时候(此时遍历便是遍历新数组了)通过key找到可复用的节点进行更新。
之后再遍历一次旧节点数组,进行无用节点的卸载。
找到需要移动的节点:如何找到需要移动的节点(双层for循环,外层为新节点数组)?如下图所示: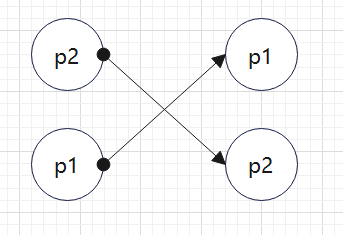
p2在旧节点中的位置为1,p1为0。我们先设置一个lastindex来记录遍历的旧节点的位置。刚开始为0。
从p2开始遍历,在旧节点中寻找 ===》为1,是大于lastindex的值0的,那么不需要移动,同时设置lastindex为1。
再遍历p1,p1找到对应的旧节点中的位置为0,小于last index,则需要移动。
简单来说,就是我(p2)在新节点中的位置在你(p1)前面,但是在旧节点中的位置你(p1)却在我(p2)前面。所以p1需要移动。
如何移动:以上为例,当我确定p1需要移动之后,可以找到p1在新数组节点中的前一个节点(p2)。同时,每一个VNode属性有一个el属性,保存着真实dom元素,再找到其兄弟节点作为锚点进行插入即可。删除元素:常规更新之后遍历一次旧元素数组,没有对应key值的删除即可。添加新元素:内层循环遍历旧元素后未找到则挂载。双端diff算法
更快的移动元素的算法,顾名思义,就是会保存两个新旧节点队列的两个端点,并反复的比较。
如图:
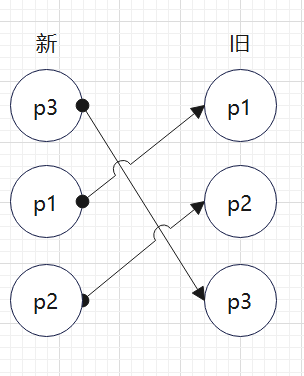
以上述为例,若是采用简单算法,则需要移动两次,其实只需要移动一次。
双端:新数组头、尾;旧数组头、尾。比较算法:四步- 旧头 === 新头?
- 旧尾 === 新尾?
- 旧头 === 新尾?
- 旧尾 === 新头?
理想情况:比如满足条件iv,那么就可以知道,旧数组尾部节点应该在最前面,所以可以将旧尾插入旧头前面(因为此时旧头对应的真实dom是第一个)。移动完毕之后,可以将新头的值-1,旧尾的+1,再进行比较。
非理想情况:如果经历四步之后一直没有找到对等元素如何处理呢?就直接找新头对应的节点在旧数组中的位置。然后将其移动到旧数组头部(移动真实dom)。然后将新头-1即可。。快速的diff算法
预处理:借鉴了纯文本diff算法的思路(只保留变量部分)找到新旧两组子节点中的相对位置不变化的元素。
步骤:理想时:从头开始,比如j,分别指向新头新尾(都为0嘛)若相等则patch,然后j自增再比较,直到不相等为止。
在从双方尾部开始遍历,一直到不相等的为止(此时当然对应的尾部索引是不一样的比如,newEndIdx、oldEndIdx)。
当遍历完毕之后用newEndIdx,oldEndIdx与j比较。若
oldEndIdx<j;说明旧节点处理完
newEndIdx>=j;说明仍有新节点未处理。
插入,找到新的节点插入对应的位置,其实就是oldEndIdx对应位置的前面即可。
非理想时:遵从上述步骤,一直到不满足为止。
及不满足
j>oldEndIdx && j<=newEndIdx(旧节点被处理完,有新的,需要被挂载)
j>newEndIdx&& j<=oldEndIdx(新节点被处理完,有旧的,需要被卸载)
创建一个与剩余新节点数相同的数组source,并填充为-1的值。同时建立索引表(key:index)方便查找,然后通过索引表寻找新数组中节点在旧数组中的位置,并将其赋值给
source然后遍历旧节点,直接通过当前遍历的旧节点的key值快速查找对应的下标然后进行比较,对source数组赋值(为-1代表是新节点)。
当得到source数组之后,再计算它的最长递增子序列。
最长子序列移动:- 什么是最长子序列?[1,6,5,12] ==> [1,6,12]
找到最长子序列之后,所需要移动的代价便为最小。
设置两个变量,分别指向最长递增子序列的末尾和新数组节点的末尾,通过判断对应节点的sourec的值是否为-1(新节点)和当前索引是否与最长递增序列的值相等(不需要移动)来进行移动即可(diff算法的时候也会增加一个moved变量)。
响应式系统:
一个响应式数据最基本的实现依赖于对读取和设置操作的拦截,从而在副作用函数与响应式数据之间发生联系。当读取操作发生时,将当前执行的副作用函数放入桶中,当设置操作发生,将对应的副作用函数取出并执行。===>根本实现原理。
effect函数
此函数的主要作用是作为依赖函数收集的入口(将当前的依赖函数保存到
activeEffect),我们可以在此对副作用函数、依赖函数进行一些操作;比如配置options选项,关联deps依赖(与当前依赖函数相关的set集合)。同时它可以接收两个参数,一个便是依赖函数,另一个是配置选项options(同时也挂载在一栏函数上),可以进行配置- 使用响应式对象存储一一对应关系的解决。使用
weakMap(只能使用对象作为键)。同时不会影响GC工作。 - 嵌套的副作用函数:很简单,采用栈的形式存储副作用函数,每次的
activeEffect取栈顶的函数,这样就算嵌套也不会影响。 - 可调度性:即是
options选项的配置,通过它,对副作用函数进行一些配置,执行时可以将配置挂载在副作用函数上,执行副作用函数时(trigger中,options.schedule中)会进行判断。
- 使用响应式对象存储一一对应关系的解决。使用
computed
computed就是使用了 effectFn + options.lazy + options.scheduler 组合的实现。
本身副作用函数是会立即执行的,通过lazy属性可以控制第一次不执行。同时返回副作用函数。
而computed函数所接收的参数更像是一个getter函数,同过返回的副作用函数,再包装成一个对象。读取的时候进行副作用函数的执行并返回对应的值,则达到效果。
function computed(getter) { const effectFn = effect(getter, { lazy: true }) const obj = { get value() { return effectFn() } } }同时我们还需要实现缓存,可以添加标志与缓存变量
function computed(getter) { let value // 缓存 let dirty // 是否改变 const effectFn = effect(getter, { lazy: true scheduler() { // 当options选项中存在scheduler,会执行scheduler,同时将副作用函数当作参数传递进来。而不是直接执行副作用函数。 dirty = true // 闭包特性改变 dirty } }) const obj = { get value() { if(dirty) { return effectFn() } return value } } }watch
watch本质上也是利用了副作用函数执行的可调度性。
effectFn+options.scheduler一个watch本身会创建一个effect(computed同是),当effect所依赖的数据发生变化的时候会执行options.scheduler函数,此时便可以在调度函数中进回调函数的调用(watch函数传入的参数)。同时可以对watch函数传递options选项(之前的是effect函数的),比如immediate:true;那么就可以直接先执行一次传入的回调函数。
toRef、toRefs
就是包装了一个对象,将reactive式的响应式对象拆解并以getter的形式返回。
function toRef (obj, key) { const wrapper = { get value(){ return obj[key] } } return wrapper }
Proxy和Reflect
Proxy可以创建一个代理对象,同时监听(拦截)对被代理对象的基本事件操作。通过对被代理对象的读取和赋值操作可以监听基本的事件,并进行依赖收集track和事件的触发trigger。当然除了基本的getter、setter外,proxy对象中总共有13种内部方法,刚好可以代理对象的所有操作,包括get、set、hasProperty、delete等。
Reflect,是一个全局对象,可以对应的对对象进行一些操作方法,比如get方法,其实就是访问对象的get默认行为。最重要的是有第三个参数receiver,相当于函数执行过程中的this。如果访问的代理对象中的属性中用到了this,那么就不会触发响应式,用receiver就很好的处理了这个问题。
对于数组,主要是监听数组长度的变化。因为数组是一个异质对象,其中的[[defineOwnProperty]]方法有所不同,需要修改数组。同时重写了有可能隐式更改数组长度的方法。并拒绝监听Symbol。
响应式系统的优化:
合理的触发响应。
每一次进行事件触发的时候判断新旧的值是否真的发生了变化(需要判断不是NAN的情况)。
浅响应与深响应。
浅响应:对普通对象来说,当前的响应都是浅响应,因为对象的属性是对象的话,监听的时候检测不到其改变即可。
深响应:监听的时候判断当前属性若是对象,则进行递归得响应包装(reactive)
只读
设置一个readOnly变量进行控制即可,当触发setter的时候进行一个判断。
keepAlive的实现原理
其实keepAlive组件本身并没有渲染额外的内容,它只是返回了它内部的组件
keepAlive一词借鉴于HTTP协议,又称为持久连接,网络中的keepAlive可以避免频繁的tcp连接和释放。vue中的keepAlive与其功能类似,可以避免一个组件频繁的被销毁和创建。keepAlive的实现需要渲染器的配合。
其本质是缓存管理,加上特殊的挂载卸载逻辑。
假卸载。
一个组件被切换的时候并不是真正的被卸载了,而是被搬运到了一个隐藏的容器之中(createElement('div'))。而再次被挂载的时候也不是真正的挂载,而是从隐藏的容器当中将组件再搬运出来。
这也对应两个生命周期函数
activated和deactivated如何实现。
通过对内部组件标记一些属性,来做相应的逻辑处理。
shouldkeepAlive:当卸载组件的时候若是检测到这个属性,便会使用keepAliveInstance中的_deactivated方法让其失效,而并非真正的卸载。keptAlive:当被缓存的内部组件再次被挂载时,会判断此标记。若存在则直接激活。即使用keepAliveInstance中的_activated方法让其激活。
include和exclude
默认情况下,keepAlive组件会对所有的内部组件进行缓存,include(需要缓存)和exclude(不需要缓存)的诞生便使得用户可以自定义缓存规则(如果两者均存在,exclude优先级更高)。内部逻辑即是多加了一层判断。
缓存管理
使用map实现的,键为vnode.type,值为vnode。可以设置最大的缓存数量(:max="2")。存储的策略是:存储最新的被访问的组件。排除最近最久未使用(LRU)。